
欢迎来到星辰在线“传媒科技速递”栏目,我们是敏锐的信息捕手,凭借对内容新鲜度与话题讨论度的精准拿捏,为您悉心筛选并编织出近期最具价值和前瞻性的科技资讯。
新年之际,我们满怀喜悦地为您拉开第一期的序幕,本期焦点将锁定在席卷全网的 DeepSeek 上。它究竟是何方神圣?又为何能在短时间内引爆全网热议?让我们一起来了解它的故事吧。
DeepSeek是什么?
DeepSeek,全称“杭州深度求索人工智能基础技术研究有限公司”(下文称中国深度求索公司),成立于2023年7月,由量化资管巨头幻方量化创立,创始人梁文锋在量化投资和高性能计算领域具有深厚的背景和丰富的经验。
2024年12月,DeepSeek推出DeepSeek-V3在全球AI领域掀起巨大波澜,它以极低的训练成本,实现了与GPT-4o等顶尖模型相媲美的性能,震惊业界。2025年1月20日DeepSeek推出新模型DeepSeek-R1,1月27日,Deepseek应用登顶苹果中国地区和美国地区应用商店免费App下载排行榜,在美国地区下载榜上超越ChatGPT。
DeepSeek大型语言模型拥有强大的自然语言处理能力,就像是一个聪明又懂你的助手,能够像朋友一样理解并回答问题。基于其背后的算法和数据,他能帮助你写代码、整理资料,甚至解决一些复杂的数学问题。

DeepSeek为何能够火爆全网?
1月27日,美国三大股指开盘即暴跌,英伟达、微软、谷歌母公司Alphabet、Meta等美国主要科技股均遭遇股市地震。其中英伟达跌近17%,单日市值蒸发约6000亿美元,创美股最高纪录。“掀翻”美股、登顶免费应用下载榜首,DeepSeek为何能够火爆全网,让硅谷和华尔街巨头“睡不着觉”?
提到大模型,大家的第一印象或是OpenAI开发的ChatGPT。DeepSeek之所以可以从众多模型之中异军突起,是因为它不仅率先实现了媲美OpenAI-o1模型的效果,更是将推理模型的成本压缩到了极低。
DeepSeek的完全开源策略不仅降低了用户的使用门槛,还促进了AI开发者社区的协作生态。通过开源,DeepSeek吸引了大量开发者和研究人员的关注,他们可以在平台上自由获取和修改模型代码,共同推动AI技术的发展。英伟达高级研究科学家JimFan在其个人社交平台表示,“我们正身处这样一个历史时刻:一家非美国公司正在延续OpenAI最初使命——通过真正开放的前沿研究赋能全人类。”

在本月世界经济论坛2025年年会开幕当天,中国深度求索公司发布其最新开源模型R1,再次引发全球人工智能领域关注。DeepSeek-R1在技术上实现了重要突破——用纯深度学习的方法让AI自发涌现出推理能力,在数学、代码、自然语言推理等任务上,性能比肩OpenAI-o1模型正式版,该模型同时延续了该公司高性价比的优势。据了解,DeepSeek-R1模型训练成本仅为560万美元,远远低于美国开放人工智能研究中心、谷歌、“元”公司等美国科技巨头在人工智能技术上投入的数亿美元乃至数十亿美元。关于价格,创始人梁文锋曾在接受媒体采访时表示,无论是API还是AI都应该是普惠的、人人可以用得起的东西。
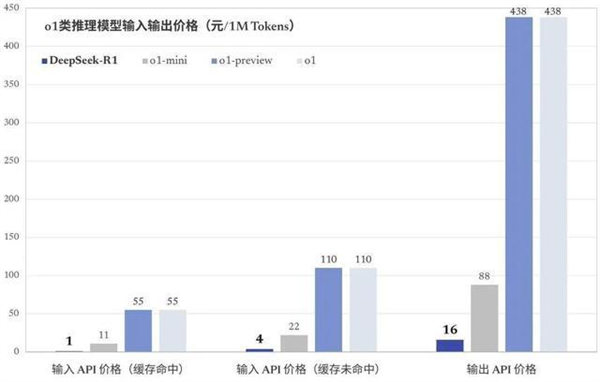
△DeepSeek R1模型与o1类推理模型输入输出价格对比(图源/DeepSeek)
DeepSeek持续引发业内震动。脸书母公司Meta已成立专门小组展开研究和学习。北京邮电大学人工智能学院人机交互与认知工程实验室主任刘伟表示,DeepSeek最大优势在于算法的改进和优化,如果说OpenAI是“大力出奇迹”,那么DeepSeek小力也可以出奇迹。
此外,值得关注的是DeepSeek采用完全开源策略。曾经OpenAI创立的初衷,是希望“以最有可能造福全人类的方式推进数字智能发展,而不受产生财务回报需求的限制”。然而在GPT-3发布之后,OpenAI限制了对模型的访问权限,在GPT-4发布之后更是隐藏了其训练数据和模型权重,完全走向了“闭源”。


DeepSeek被大规模网络攻击
1月28日,深度求索(DeepSeek)官网显示,其线上服务受到大规模恶意攻击,DeepSeek这次受到的网络攻击,IP地址都在美国。

图源:deepseek官网
周鸿祎公开喊话:如果DeepSeek有需要,360愿意提供网络安全方面的全力支持。同日,360发布《关于全力支持国产大模型DeepSeek的倡议书》,作为国内最大的网络安全公司,360集团郑重承诺:我们将以民族大义为己任,全力以赴为DeepSeek提供全方位网络安全防护,坚决捍卫国产AI技术的尊严与安全。

1月30日凌晨,即农历大年初二,奇安信XLab实验室监测发现,针对DeepSeek(深度求索)线上服务的攻击烈度突然升级,其攻击指令较1月28日暴增上百倍。XLab实验室观察到,至少有2个僵尸网络参与攻击,共发起了两波次攻击。 “僵尸网络的加入,标志着职业打手已经开始下场,这说明DeepSeek面对的攻击方式一直在持续进化和复杂化,防御难度不断增加,网络安全形势愈发复杂严峻。”奇安信XLab实验室安全专家表示。
网络安全专家分析,从所遭遇的攻击可以看出,随着我国在科技领域的不断崛起,国外黑客的恶意攻击也日益增多。这些攻击不仅可能导致服务中断、数据泄露等严重后果,还可能对我国的科技形象和国际竞争力造成负面影响。因此对于所有企业而言,亟须加强网络安全防护。

DeepSeek团队:90后、95后为主
DeepSeek创始人梁文锋是吴川市覃巴镇米历岭村人,父母都是小学语文老师。“85后”的梁文锋从小就是“学霸”,在数学方面天赋突出。同学们反映,梁文锋并非“书呆子”类型,而是很有独立思考的精神。梁文锋本科和硕士都就读于浙江大学,2008年,研究生毕业的梁文锋并没有走上“码农”的道路。当时推崇“量化投资之父”西蒙斯的他和朋友一起在出租屋内刻苦钻研,想要找到对股票价格建模的方法。

梁文锋(右)参加工作座谈会
2010年,沪深股指期货推出,这给了梁文锋充分发挥计算机建模天赋的机会。很快他的自营资金盘就达到了5亿元的水平。2015年,梁文锋与校友一起共同创立幻方量化,在A股市场系统性地进行量化交易。2021年,幻方量化的资产管理规模达到千亿水平,被誉为国内四大顶级量化私募之一。
幻方量化的成功离不开人工智能的深度融合,梁文锋很早就产生了用AI自动制定量化交易策略的想法,并坚持不懈地付诸实践。2020年,英伟达发布了A100芯片,这是英伟达下一代旗舰作品,而幻方量化成为亚太地区第一批拿到货的客户。幻方量化多年来不仅储备了大量的尖端芯片,而且在软件算法层面不断推陈出新,这给梁文锋在AI领域的创业奠定了扎实的基础,2023年7月他创立了DeepSeek(全称“杭州深度求索人工智能基础技术研究有限公司”)。
据报道,DeepSeek的员工规模不到140人,是Open AI的十分之一左右。据领英网站检索样本发现,DeepSeek员工85%以上拥有硕士学位,40%以上有博士学位。团队成员平均年龄约为28岁,90后占比超75%,95后(1995年后出生)员工占比50%以上。该公司成员大多毕业于北大、清华、中科大等国内顶尖院校,也有少数毕业于麻省理工学院、卡内基梅隆大学等海外知名高校。同时DeepSeek的员工中也有相当一部分具有交叉学科背景。

多方发声,世界对DeepSeek的惊叹还在持续
美国总统特朗普称,DeepSeek为美国人工智能行业敲响“警钟”。对于DeepSeek的横空出世,西方媒体一方面猜测这在美国严格限制对华芯片输出的情况下是如何实现的,另一方面又在渲染这是“人工智能的斯普特尼克时刻”——暗示其意义堪比冷战时期苏联发射人类第一颗人造卫星对美国形成的冲击。
英国《卫报》称,DeepSeek并非唯一一家在美国阻止先进科技产品运往中国的情况下进行创新的中国公司。卡内基国际和平基金会研究员马特·希恩表示:“如果美国政府认为我们只需要击败DeepSeek就可以了,那么我们会大吃一惊。”
印度铁道、通信以及电子和信息技术部长阿什维尼·瓦伊什瑙当地时间周二(28日)称赞DeepSeek以其低成本的AI模型震撼了该行业,并在谈及DeepSeek节省成本的做法时,提到印度政府努力建立本地化AI模型一事。
日本《朝日新闻》网站29日刊登的文章说,中国人工智能(AI)企业深度求索公司日前发布最新模型DeepSeek-R1,以高性能、低成本等特点受到全球关注。《朝日新闻》报道说,目前DeepSeek-R1模型和深度求索公司此前公开的DeepSeek-V3模型都可以在线免费使用,也能用日语对话。
多家海外科技巨头对DeepSeek表现出开放态度,陆续宣布接入DeepSeek模型。据香港《南华早报》报道,1月30日,英伟达在官方网站宣布,DeepSeek-R1模型可作为NVIDIA NIM微服务预览版使用,称该模型为需要逻辑推理、数学、编码和语言理解的任务提供了“最先进的推理能力”“高推理效率”以及“领先的准确性”。
资料来源:央视财经、新闻联播、环球网、中央广电总台中国之声、央视网、新晚报、玉渊谭天、红星新闻、北京日报微信公号

策划 | 肖湘 李正希
编辑 | 潘丹荔